




 一覧
一覧

斉藤 孝 【略歴】
概念理論と情報インデックス
斉藤 孝/中央大学文学部教授
専門分野 記録情報学
概念理論とは、哲学的な厳しい名前ですが意外なことにICT世界では情報インデックスというものに用いられ、意味を解するSemantic Webに利用されます。
まず情報インデックスとは何か
古代アレクサンドリア図書館の司書であったカリマコス(前305年頃)が編纂したという『スーダ』は120巻の及ぶパピルスの書誌目録でした。それはパピルスの書籍の標題を明らかにしただけでなく、出典や所有者までを索引した書誌目録でした。これが情報インデックスの起源です。
なぜ概念理論が必要になるのか
人は世界を理解しようとする時、あらかじめ大まかな略図を持っています。これが概念の枠組み(スキーマ)といえるものです。その昔、書籍というスキーマを学びとることをリテラシーといいました。その原語のリテラ(Litera)が表しています。それは文字で表された主題は抽象化された概念であり、いかにして実世界の具体像に対応付けて描くかという文字の解読能力のことでした。リテラシーは、表層に現れた文字だけでなく、深層に潜む概念の構造を認識することも目的でした。人は絶えず押し寄せる情報に意味を与えるために、思考や世界観についてのスキーマを学んできました。簡単な例を示してみます。ここに「斉藤孝 中央大学 情報学」と「今井悠真 東京大学 医学」の2つの記録があるとします。この2つの記録は、漢字の文字列(データ)に過ぎなく、このままでは何を意味する記録であるかは不明です。もし誰かが「氏名 所属 専攻」という項目を考えて、記録に対応づけたとします。彼は「名簿」を表すものではないかという概念を頭に描いたからです。その概念こそが主題であり、その記録に意味を与えるものです。それは「名簿(氏名、所属、専攻)」という枠組みとして主題の構造を表します。そこで1つの情報化の視点となったものであるからスキーマと呼ぶことにします。この事例のスキーマは、「名簿(氏名、所属、専攻)」という概念文法によって定義されたものです。このような概念文法を情報インデックスは用います。この例では「氏名(斉藤孝、今井悠真)、所属(中央大学、東京大学)、専攻(情報学、医学)」という分類を用いることで、それぞれの文字データは意味を持つことになります。このような情報インデックスの概念文法を考察するために概念理論が研究されてきました。
情報インデックスのプログラミング
Webにおいて不可欠なサーチエンジンやポータルサイトと呼ぶデジタル・ライブラリは情報インデックスに支えられています。そのプログラミングを見てみましょう。次のような記録を対象にします。
「その記録は、60分の音楽の録音であり、”mp3”で圧縮コード化されたデジタル・ファイルである。録音の内容は、”東京劇場”において演奏され、演奏曲は”幻想曲”というもので、オーケストラの”自然管弦楽団”によって行われた。演奏日時は、”2011年8月16日午後5時”で、使われた楽譜は”バイオリン・コンチェルト”である。音楽著作権は、”東京劇場”と”自然管弦楽団”が所有する。」
この主題分析は図1に示した概念文法よって表さすことができます。すなわち、「Event」を基にして「Comp (演奏曲)、Audio (音質)、Context(解説)、Act(演奏者)」の概念を明らかにしたスキーマ(概念文法)です。このスキーマは、「Event」と「Comp」とは入力関係であり、「Audio」とは出力関係であり、「Comp」の属性として「Title」と「Type」があり、「Act」の属性として「Agent」と「Role」があることを表します。さらに詳しく「Audio」の例では、「Format、 Type、 Place.Performance、 Time.Performance 、Date.Performance、 Agent.Orchestra、 Relation.isPerformanceOf」などの項目と概念構造が明らにされています。これらの概念の属性項目には名前を付けておきます。概念はメタデータとしてそのまま使用されます。定義されたメタデータには実際のデータを代入して使います。例えば、「Format :: MP3」や「Place.PerformanceOf :: 東京劇場」というデータを代入します。以上の手順によって情報インデックスの項目となるメタデータを明らかにする設計は終わります。次の手順は、メタデータ言語を用いたプログラミングです。メタデータ言語の語彙は「< >」で囲まれたもので、タグと呼びます。
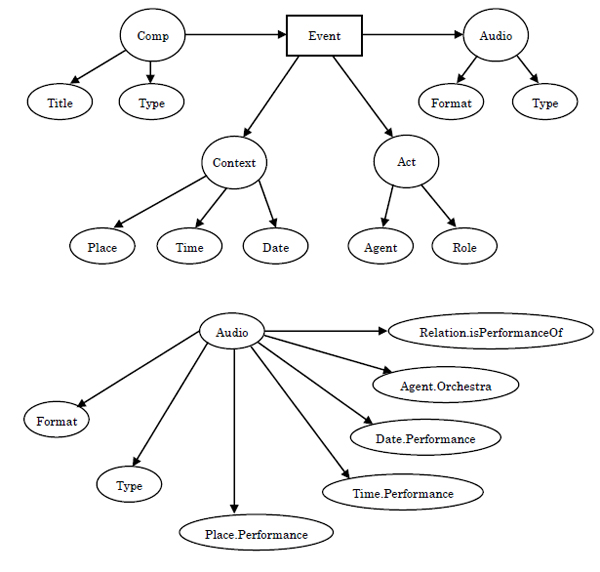
図1 概念文法(スキーマ)の例
情報インデックスのプログラム例
<Resource id="audioTac">
<Title>自然管弦楽団の演奏</Title>
<Date.Performance>2011年8月16日</Date.Performance>
<Time.Performance>17:00</Time.Performance>
<Place.Performance>東京劇場</Place.Performance>
<Agent.Orchestra>自然管弦楽団</Agent.Orchestra>
<Relation.isPerformanceOf>comp10</Relation.isPerformanceOf>
<Description>バイオリン・コンチェルト</Description>
<Rights>東京劇場と自然管弦楽団</Rights>
<Type>audio</Type>
<Format>MP3</Format>
<Length units="mins">60</Length>
</Resource>
オントロジという概念理論
情報インデックスの研究は、概念理論を加熱させます。どこにも様々な概念は見出せ、それらを集めていくと、どんどん人間的になります。どうしてもわからない概念があったら、それこそが人間にとって根源的なものに違いありません。哲学的課題ですが、今ではオントロジという概念理論となりました。
参考文献

- 斉藤 孝『デジタルメディアの情報インデックスと知識地図の研究』 中央大学出版部
A5判348頁 ISBN 978-4-8057-6181-6 2012年発行
- 斉藤 孝(さいとう・たかし)/中央大学文学部教授
専門分野 記録情報学 - 1942年生まれ。1969年慶応義塾大学大学院図書館・情報学修士課程修了、1969年~1984年 (株)東芝電子計算機システム技術部勤務、1984年~1990年愛知淑徳大学教授、1990年から中央大学文学部教授、現在に至る。その間、2002年カリフォルニア大学デービス校客員教授。主な著書に『記録・情報・知識の世界(2004年)』、『意味論からの情報システム(2006年)』、『リレーショナルデータベース教科書(2009年)』、『社会科学情報のオントロジ(2009年)』、『デジタルメディアの情報インデックスと知識地図の研究(2012年)』がある。