



Top>Opinion>Concept Theory for Information Index
 Index
Index

Takashi Saito [profile]
Concept Theory for Information Index
Takashi Saito
Professor, Faculty of Letters, Chuo University
Area of Specialization: Documentation Science
Although concept theory may sound like an imposing philosophical term, it is index in the information and communication technology (ICT) field and used in the Semantic Web to interpret meaning.
Firstly, what is information index?
The Suda was a bibliography composed of 120 papyrus volumes that was compiled around 305 BC by Callimachus, who was a librarian at the ancient Library of Alexandria. The bibliography not only identified the titles of papyrus books, but it also indexed them by sources and owners. The Suda was the original information index.
Why is concept theory necessary?
When people try to understand the world, they usually already have a general idea in place. This can be described as a concept theory framework (schema). In the past, learning through the schema of books was referred to as literacy. The word literacy expresses its source word, litera. This is a concept of abstracting subjects in characters, and a measure of the ability to interpret these characters so that they respond as close as possible to their concrete images in the real world. The purpose of literacy is not just the understanding of the letters on the surface level, but also the understanding of the structure of the deep underlying concepts. People have learned schema relating to thinking and worldviews in order to give meaning to the information theory are constantly coming into contact with. Let's look at a simple example. Imagine that we have two records "Takashi Saito, Chuo University, information science" and "Yuma Imai, Tokyo University, medicine." These two records are only character strings (data), and as they are it is unclear what these records mean. Let's assume that someone thinks of "name, affiliation, and specialty" and associates these concepts with the record. This association is made because that someone assumes that the record expresses a name list. That concept itself is the subject which grants meaning to the records. The subject's structure is expressed as the framework of a name list (name, affiliation, and specialty). The framework can be referred to as a schema, as it is a viewpoint which has associated data to form a unit of information. In this case, the schema is defined by the concept grammar of a name list (names, affiliation, and specialty). Information index uses this form of concept grammar. In this example, using the classifications of name (Takashi Saito and Yuma Imai), affiliation (Chuo University and Tokyo University), and specialty (information science and medicine) gives meaning to the character data. Concept theory has been researched to provide insights on the concept grammar for information index.
Information index programming
Digital libraries called search engines and portal sites that are essential for the web are supported by information index. Let's take a look at programming next, using the following record as an example.
"This record is a 60 minute musical recording which is a digital file compression-coded in the mp3 format. The contents of recording consist of the piece entitled Fantasia performed at the Tokyo Gekijo by the orchestra entitled the Natural Orchestra. The date and time of the performance was August 16, 2011 at 17:00, and the score used was a violin concerto. Music copyrights belong to the Tokyo Gekijo and the Natural Orchestra."
A subject analysis can be expressed as in the concept grammar displayed in Figure 1. The schema (concept grammar) clarifies the concepts of Composition, Audio, Context, and Act centered around an Event. In this schema, Event and Comp have an input relationship, Audio has an output relationship, the attributes of Comp are Title and Type, and the attributes of Act are Agent and Role. In further detail, for the Audio example, the items of Format, Type, Place.Performance, Time.Performance, Date.Performance, Agent.Orchestra and Relation.isPerformanceOf and the concept structure are clarified. The attribute items of these concepts are named. These concepts are used as is as metadata. Defined metadata is used by assigning actual data. For example, data such as "Format: MP 3" or "Place.PerformanceOf: Tokyo Gekijo" can be assigned. Through the above process, design that clarifies the metadata that serves as the information index is completed. The following procedure is programming using metadata language. Metadata language terms are surrounded by <> marks referred to as tags.
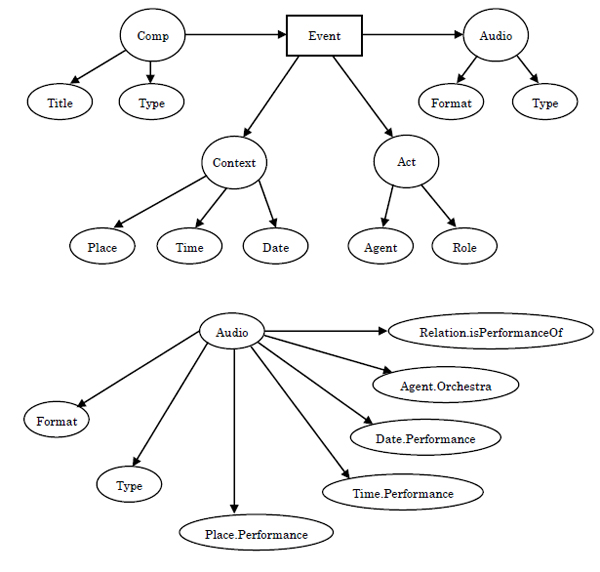
Figure 1: Example of conceptual grammar (schema)
Information index program example
<Resource id="audioTac">
<Title>Natural Orchestra Performance</Title>
<Date.Performance> August 16, 2011</Date.Performance>
<Time.Performance>17:00</Time.Performance>
<Place.Performance > Tokyo Gekijo </Place.Performance >
<Agent.Orchestra>Natural Orchestra</Agent.Orchestra>
<Relation.isPerformanceOf>comp10</Relation.isPerformanceOf>
<Description>Violin Concerto</Description>
<Rights>Tokyo Gekijo and Natural Orchestra</Rights>
<Type>audio</Type>
<Format>MP3</Format>
<Length units="mins">60</Length>
</Resource>
The concept theory as an ontology
Information index research accelerates the development of concept theory. Various concepts can be found everywhere, and they become more and more human as we collect them. Concepts that are incomprehensible must be fundamental ones for humans. This philosophical issue is the concept theory referred to as ontology.
References

- Takashi Saito, Digital Media Information Indexing and Knowledge Map Research [Dejitaru Medeia no Joho Indekkusu to Chishiki Chizu no Kenkyu] (Chuo University Press)
A5 size, 348 pages, ISBN 978-4-8057-6181-6, published in 2012
- Takashi Saito
Professor, Faculty of Letters, Chuo University
Area of Specialization: Documentation Science - Born in 1942. After acquiring a master degree in library and information science from Keio University Graduate School in 1969, he served in the Computer Systems Engieering Department at Toshiba from 1969 to 1984. He then served as a professor at Aichi Shukutoku University from 1984 to 1990, before serving at his current position as professor on the Faculty of Letters, Chuo University from 1990 to the present day. He also served as a visiting professor for the University of California, Davis in 2002. His major publications include The World of "Documentation, Information, and Knowledge" ["Kiroku, Joho, Chishiki" no Sekai] (2004), Information Systems from Semantics [Imiron kara no Joho Shisutemu] (2006), Relational Database Textbook [Rireshonaru Detabesu Kyokasho] (2009), Ontology of Social Science Information [Shakai Kagaku no Ontoroji] (2009), and Digital Media Information Indexing and Knowledge Map Research [Dejitaru Medeia no Joho Indekkusu to Chishiki Chizu no Kenkyu] (2012).
- Research Activities as a Member of Research Fellowship for Young Scientists (DC1), Japan Society for the Promotion of Science (JSPS) Shuma Tsurumi
- Important Factors for Innovation in Payment Services Nobuhiko Sugiura
- Beyond the Concepts of Fellow Citizens and Foreigners— To Achieve SDGs Goal 10 “Reduce Inequality Within and Among Countries” Rika Lee
- Diary of Struggles in Cambodia Fumie Fukuoka
- How Can We Measure Learning Ability?
—Analysis of a Competency Self-Assessment Questionnaire— Yu Saito / Yoko Neha - The Making of the Movie Kirakira Megane